Motivation
The time-series database InfluxDB provides a HTTP API to write data. Data points (measurements) are inserted via a Line protocol, which allows batching of data by writing multiple points in one HTTP request.
While experimenting for a simple InfluxDB C++ client, I wanted to create an asynchronous fire-and-forget API, so that the data points can be sent over HTTP without blocking the instrumented C++ code. Several “readymade” options to implement concurrency in this scenario are available.
A simple PAIR of ZeroMQ sockets would do the job, but I’d have to implement batching separately. Thus, I turned my attention to a higher-level abstraction: Rx
Rx Window Operator
Quickly looking through the cross-language Reactive Extensions site, I found the right operator: Window.
This operator has luckily been implemented in RxCpp, thus I proceeded with the experiment.
Batching Design
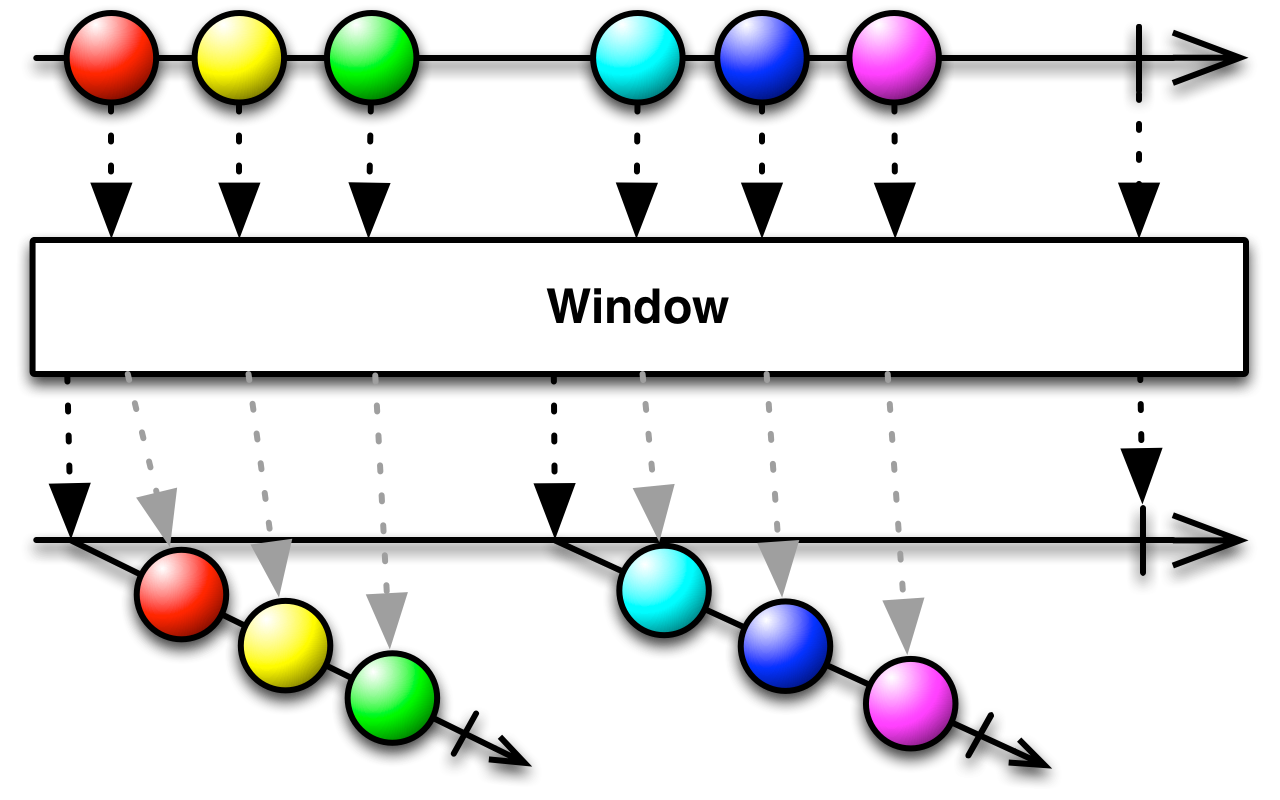
Rx Window Operator (CC BY 3.0 reactivex.io)[1. Source: reactivex.io License: (CC BY 3.0)]
The window operator takes an observable sequence of data and splits it into windows (batches) of observables. To batch requests, the observable windows of data are aggregated to a single value upon the last value from the windows (via other aggregating Rx operators).
A Toy Problem
To validate the approach, the following problem is set:
Given a stream of integers, append the integers into a series of strings, either every second, or every N integers
String appends with integer-to-string conversions in C++ will be done via the {fmt} library.
Batching in One Line of Code
A stream of numbers batched either by time or count:
auto values = rxcpp::observable<>::range(1, 1000'000)
.window_with_time_or_count(std::chrono::seconds(1), 100'000);
Note, there is an almost one-to-one translation into a C# version:
var values = Observable.Range(1, 1000000)
.Window(TimeSpan.FromSeconds(1), 100000);
This indicates the power of the Rx abstraction across languages. The Rx website provides just the right sorting of the documentation to be able to translate Rx code from one language to another.
Aggregating the Batches
In order to do something useful with the batched data, the Scan operator is used to gather the data in a string buffer, and after the last value has been received, the string buffer is assembled into a string and processed:
values.subscribe(
[](rxcpp::observable<int> window) {
// append the number to the buffer
window.scan(
std::make_shared<fmt::MemoryWriter>(),
[](std::shared_ptr<fmt::MemoryWriter> const& w, int v)
{
*w << v;
return w;
})
// what if the window is empty? Provide at least one empty value
.start_with(std::make_shared<fmt::MemoryWriter>())
// take the last value
.last()
// print something fancy
.subscribe([](std::shared_ptr<fmt::MemoryWriter> const& w) {
fmt::print(
"Len: {} ({}...)\n",
w->size(),
w->str().substr(0, 42)
);
});
}
);
The Tale of Two Bugs
In the initial (non-TDD) spike, the batching seemed to work, however, something caught my attention (the code bites back):
[window 0] Create window Count in window: 170306 Len: 910731 (123456789101112131415161718192021222324252...)
the window wasn’t capped at 100’000. This could have been either a misunderstanding or a bug, thus I formulated a hesitant issue #277. As it turned out, it indeed was a bug, which was then fixed in no time. However, the first bug has hidden another one: the spike implementation started to crash at the end: when all the windows were capped by count, and not by time, last window was empty, as all values fit exactly into 10 batches.
The Last operator rightly caused an exception due to an empty sequence. Obviously, there’s no last value in an empty sequence. Rubber Ducking and a hint from Kirk Shoop fixed the issue by utilizing the StartWith operator to guarantee, the sequence is never empty. An empty string buffer can be ignored easier downstream.
Active Object
The active object pattern was applied to implement a fire-and-forget asynchronous API. A Rx Subject to bridge between the function call and the “control-inverted” observable:
struct async_api {
//...
rxcpp::subjects::subject<line> subj;
//...
async_api(...)
{
auto incoming_requests = subj
.get_observable()
.map([](auto line) {
return line.to_string();
});
incoming_requests
.window_with_time_or_count(
window_max_ms,
window_max_lines,
// schedule window caps on a new thread
rxcpp::synchronize_new_thread()
)
.subscribe(...)
;
}
// fire-and-forget
void insert(line const& line)
{
subj
.get_subscriber()
.on_next(line);
}
};
in order not to block the caller (which would be the default behavior), the observable watches the values from each window on a new thread. Here, scheduling on a thread pool (currently missing in RxCpp) would probably be beneficial.
While this implementation might not be an optimal one, the declarative nature of Rx, once the basics are understood, allows to “make it work and make it right” pretty quickly by composing the right operators.
Code
The runnable code of the example can be found at Github: C++ version.
In order to show, how similar the high level code can be between different languages when writing, I’ve “ported” the example to C# [2. The C# version appears to run faster on my windows machine while solving the same toy problem].