Introduction
This is the next post in the reactive examples series. Previous articles focused on building a MVVM-style ReactiveUI-based Windows application in C# with the help of Reactive Extensions. The example application had some simple word counting logic and a background ticker, demonstrating an implementation without using error-prone callbacks or explicit threading. This article will try to re-create the same application for the web browser using Vue.js, Bootstrap-Vue and vue-rx.
The result looks like this:
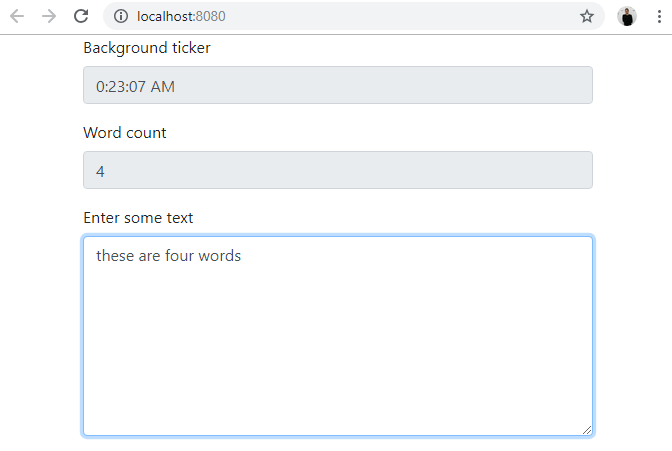
In the Meanwhile
The Actor Model
After several attempts to implement the example with RxJavaFX, I gave up on RxJava for a UI, and focused on another approach to writing concurrent reactive software: the Actor Model. This lead me to converge on two* Actor Model languages, Pony and Elixir/Erlang, and later, on one framework: Vlingo (thanks to a serendipitous meeting and a kind invitation to an IDDD workshop by Vaughn Vernon).
The venture resulted in several presentations, including one at the Lightweight Java User Group München Meetup. In the preparation for the meetup, I have demonstrated how Reactive Extensions can enhance actor model code with time-based operators, and how the transition between the paradigms is achieved (see vlingo_experiments/batching_with_rx).
As late Pieter Hintjens said and wrote, alluding to Conway’s Law, “read about the Actor model, and become a message-driven, zero shared state Actor”. The 1973 paper by Carl Hewitt and others on the Actor Model was published in proceedings of an artificial intelligence conference of the time. There are good indications that this concurrency model is a good fit for a computational model of the brain (see 1, 2).
All this deserves another series of blog posts.
In the Browser
The Actor Model is coming to the browser too: it is a natural fit for the modern web. See the talk: Architecting Web Apps – Lights, Camera, Action! (Chrome Dev Summit 2018) and the related Github project: PolymerLabs/actor-boilerplate. It has been seen in other places too, such as in the emerging framework Tarant.
Alas, I can’t show an actor model example in the browser, yet. Thus, back to Reactive Extensions!
How to get to vue-rx?
It seems, in the world of web front-end programming, there are numerous diverging paths, all of which, in the end, converge on downloading half the internet of little script files in various dialects of JavaScript. But don’t despair, commit often and small. I am not native to the JS world, and previous attempts to re-create the example in the browser failed miserably.
Vue.cli
The path chosen here is to start with a boilerplate generated with Vue CLI 3.
vue create vue-rx-example
Dependencies
Install the dependencies via npm install:
- vue – the sensible MVVM library for the browser
- moment – to format time
- rxjs, rxjs-compat, vue-rx – the Rx libraries required in this context
- bootstrap-vue – a responsive web page design pattern
The View Component
Replacing the generated view boilerplate, the following remains:
<template>
<b-form>
<b-form-group label="Background ticker">
<b-form-input readonly type="text" v-model="ticker" />
</b-form-group>
<b-form-group label="Word count">
<b-form-input readonly type="text" v-model="countWords" />
</b-form-group>
<b-form-group label="Enter some text">
<b-form-textarea v-model="text" style="min-height: 200px" />
</b-form-group>
</b-form>
</template>
which is a simple form with two read-only text fields, and one input text area, all declaratively bound to the viewmodel via the v-model directive
The ViewModel & Vue Extensions
The dependencies must be registered with Vue in the <script /> tag in order for them to work together as intended (excluding some CSS/other boilerplate):
import Vue from "vue"; import VueRx from "vue-rx"; import Rx from "rxjs/Rx"; import BootstrapVue from "bootstrap-vue"; Vue.use(BootstrapVue, VueRx, Rx); // here comes the ViewModel
The following is all of the ViewModel with the explanations in the comments:
export default {
name: "HelloWorld",
data() {
// input field is bound to this
return {
text: ""
};
},
// rx-vue part
subscriptions: function() {
// watch the input data as an observable stream
const countWords = this.$watchAsObservable("text")
// update only if not typing for 1/2 s
.debounceTime(500)
.pluck("newValue")
.startWith("")
// count the words
.map(val => {
const s = val.trim();
return s == "" ? 0 : s.split(/\s+/).length;
});
// tick the timestamp every second
const ticker = Observable.interval(1000 /* ms */).map(_ =>
new moment().format("H:mm:ss A")
);
return { countWords, ticker };
}
};
which a Rx.Net developer might find familiar:
this.WhenAnyValue(x => x.TextInput)
.Where(x => !string.IsNullOrWhiteSpace(x))
.Select(x => x
.Split()
.Count(word => !string.IsNullOrWhiteSpace(word)))
.ToProperty(this, vm => vm.WordCount, out _WordCount)
;
Observable
.Interval(TimeSpan.FromSeconds(1))
.Select(_ => DateTime.Now.ToLongTimeString());
.ToProperty(this,
ticker => ticker.BackgroundTicker,
out _BackgroundTicker)
;
Conclusion
Reactive Extensions have proven to be a suitable paradigm for building reactive user interfaces, landing them on the Thoughtworks Radar into the Adopt ring. Rx implementations can be used in variety of technologies, as the Reactive Trader project has shown.
While the Actor Model shines on the server, reactive, message-driven technologies play well together, and, perhaps, soon it will be natural to structure applications as a mix of stream-based and actor-based components.
Source code: https://github.com/d-led/vue-rx-example
Demo: https://ledentsov.de/static/vue-rx-example