Motivation
Today’s software is often connected, be it for automatic desktop updates or for implementing an internet-scale service. Developers’ tools or toys are no longer solely editors or compilers, but also databases, logging or search services, code sharing platforms, or Continuous Integration servers. Evaluating distributed on-premise software has not been as easy as desktop software, however. Arduous and error-prone installation instructions seem out of place, but are still very common. A number of open source software now comes with a one(or two)-liner installation that is always up to date. GoCD is one of them.
While discovering features of GoCD I sometimes wished for even more simplicity and automation: a one-liner for a whole Continuous Integration environment. This should include a server, several build agents, and several source repositories. With a recent push towards containerized software delivery, the path is quite clear: build, provision and configure the whole infrastructure from code and run it in containers. This way, it is easier to experiment, build and communicate Continuous Delivery prototypes.
Versions
06.09.2017: GoCD is undergoing rapid evolution, which means the details presented in this blog post may change. The GitHub repository contains the version-specific configuration in detail that is known to work.
GoCD Infrastructure as Code
There are official GoCD Docker images for both the server and base images for the build agents. The containers are configured such that the build agents can register themselves automatically with the server if the auto-registration key of the server is known.
Thus, starting from the official Docker images, to get to a one-liner self-contained infrastructure installation, the following ingredients are missing:
- starting the server and the agents
- provisioning the agents to contain desired compilers
- adding source code repositories to be built
Docker Compose as a Powerful Toy
Docker Compose is a tool to define and run multi-container applications. It is so pragmatic that using it almost feels like playing.
To start the server and an agent, the following Docker Compose configuration would suffice:
go-server:
image: gocd/gocd-server:v17.9.0
ports:
- '8153:8153'
- '8154:8154'
goagent:
image: gocd/gocd-agent-alpine-3.5:v17.9.0
links:
- go-server
environment:
GO_SERVER_URL: https://go-server:8154/go
Running docker-compose up -d pulls and brings up the minimal infrastructure.
A Custom Build Agent
In the configuration above, the agent is rather empty, and probably does not contain the build infrastructure we need.
Here, we extend the gocd/gocd-agent-ubuntu-16.04:v17.9.0 image, installing some Lua infrastructure:
FROM gocd/gocd-agent-ubuntu-16.04:v17.9.0
RUN apt-get update && apt-get install -y --force-yes \
luarocks \
ca-certificates-java
RUN update-ca-certificates -f
RUN luarocks install busted
In the docker-compose configuration, the image tag is replaced with a build one:
goagent_lua:
build:
context: .
dockerfile: Dockerfile.lua-agent
links:
- go-server
environment:
AGENT_AUTO_REGISTER_KEY: '123456789abcdef'
AGENT_AUTO_REGISTER_RESOURCES: 'gradle,java,lua'
GO_SERVER_URL: https://go-server:8154/go
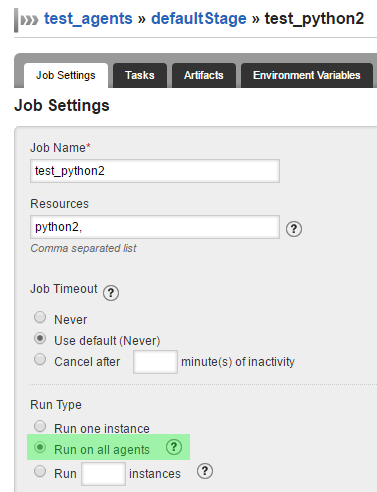
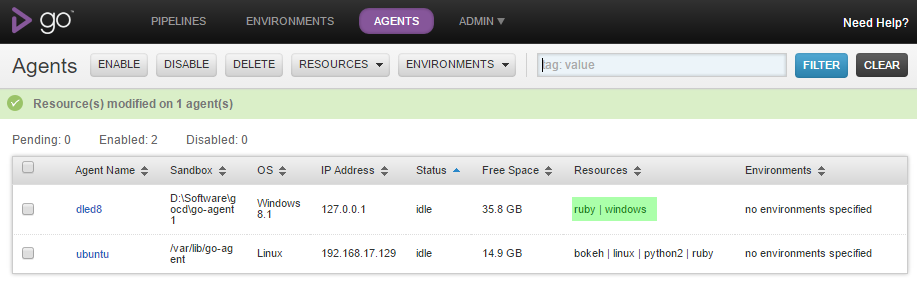
Note the resources that can be assigned to the build agents from the docker-compose file and get passed to the agent container as environment variable for correct automatic registration with the server.
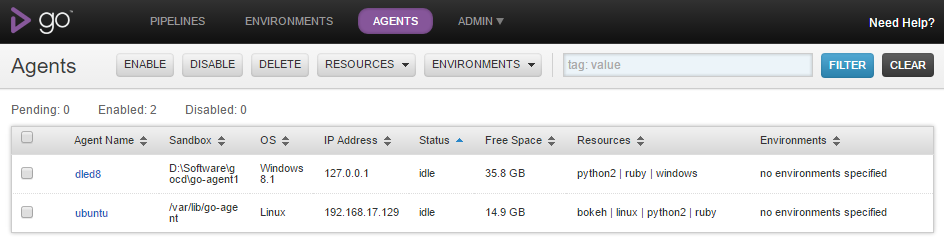
After bringing up the infrastructure and the auto-registration key matches that of the server, the agents are registered with the server:
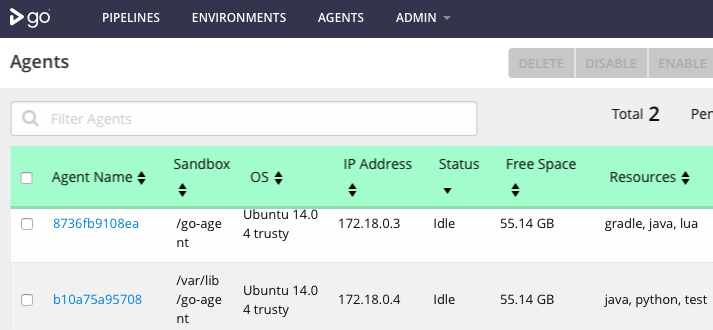
25.3.2017 Update: in the GoCD 17.3.0 server image, the auto-registration key is a generated one, and is not set to the default above. To enable auto-registration, the provisioning step is used.
Pipeline →⇉→ as Code
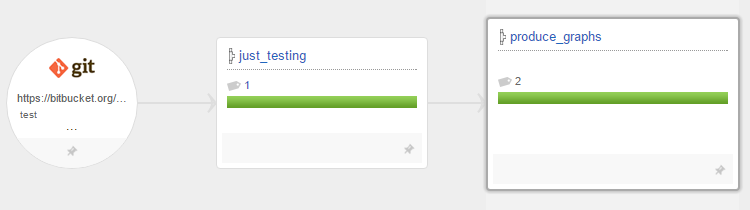
The final missing piece of the self-provisioning CD infrastructure is the addition of the repositories to be built. There is a number of GoCD management libraries on Github. Each would probably serve the purpose of setting up the pipelines.
The approach taken here is to centrally manage a list of repositories to be built, while delegating the details of each pipeline to the corresponding repository. This way, the pipeline configuration is part of the repository itself (pipeline as code), and could be portable between different GoCD instances.
The three ingredients are: the pipeline configuration from source control feature #1133, the YAML Config Plugin, and the GoCD REST API, as of the time of the experiment, none of the tools I have seen could add the pipeline-as-code configuration.
Update 10.08.2017: as of GoCD v17.8 the YAML Config plugin is bundled with the server
Update 06.09.2017: as of GoCD v17.9 the plugin identification tag is now pluginId
Adding the Pipelines (External Provisioning)
for a simpler provisioning via mapping (or copying) a config file into the container, see the next chapter
To configure the server with the pipelines, and set the auto-registration key, a separate container runs a Python script once. This way, provisioning is decoupled from the generic server configuration and can be replaced by another mechanism without rebuilding the server image. The script provisions the server with the pipelines, and sets the auto-registration key to the one agreed upon.
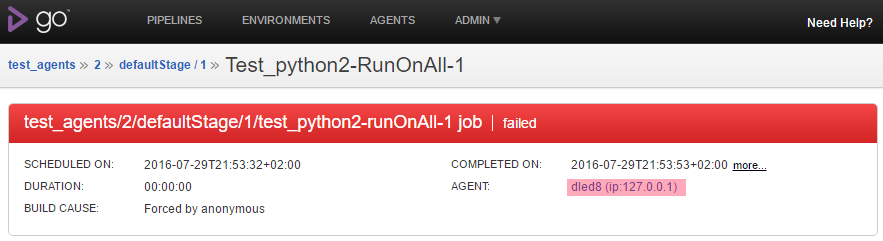
A common problem is the startup sequence of the containers. Trying to provision the server before it is ready to accept configuration would result in an error. Thus, the provisioning script tries to avoid pushing the configuration too early by waiting for the GoCD web UI to become available. This is accomplished by waiting using urlwait:
if not wait_for_url("http://go-server:8153", 300):
print("""Go server did not start in a timely fashion.
Please retry docker-compose up provisioner""")
sys.exit()
The repositories to configure pipelines from are (here, rather crudely) added directly to the XML config as the yaml config plugin expects them. The XML is first read from the /go/api/admin/config.xml API, then simply extended with the necessary tags, and then posted to the same URL. There is still a chance of a race condition that the configuration is changed between it is read and it is written. As GoCD validates the config upon modification, and the script strives to be idempotent, re-running the container should fix the conflict.
The GoCD XML config needs the following addition for a repository to configure a pipeline:
<config-repos> <config-repo pluginId="yaml.config.plugin" id="gocd-rpi-unicorn-hat-monitor"> <git url="https://github.com/d-led/gocd-rpi-unicorn-hat-monitor.git" /> </config-repo> </config-repos>
In the repository itself, place a ci.gocd.yaml with a corresponding pipeline definition.
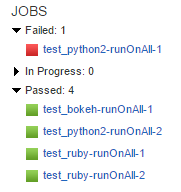
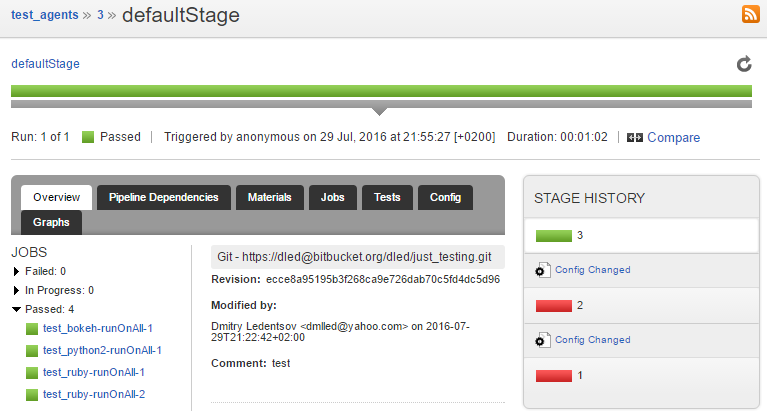
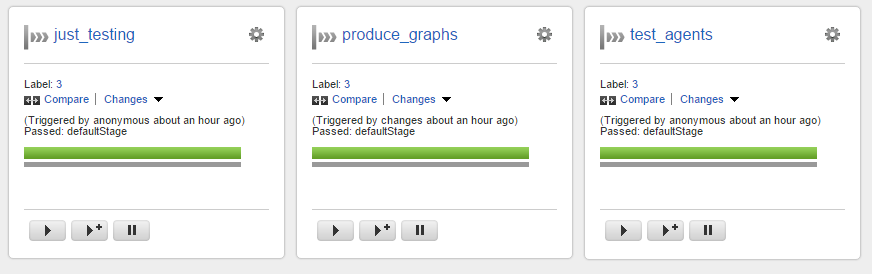
After grabbing a coffee, the infrastructure has been started, provisioned and configured, and the UI shows the result:
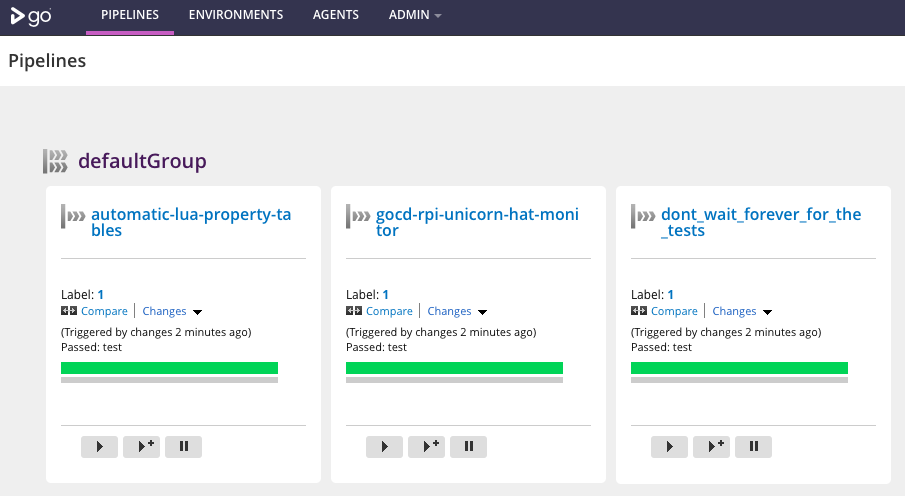
Yet Simpler Self-Provisioning
With the current official Docker image for the server, it is possible to map (or copy) configuration-relevant files and folders into the container. In our case this means, the plugin, and the whole server configuration can be directly mapped into the container, thus, provisioning the server without an extra provisioning step.
As GoCD keeps the pipeline configuration in a single file cruise-config.xml, we can simply track it in the same repository as the Docker Compose config. To map the configuration, and the plugin jar, the volumes are added to the container config:
go-server:
image: gocd/gocd-server:v17.9.0
volumes:
- ./server_home/config/cruise-config.xml:/godata/config/cruise-config.xml
Update 10.8.2017: for the demo portability reasons the configuration is copied into the container.
When the server starts, it already has most of its configuration. As the agent auto-registration key is part of the XML config, the agents will automatically register themselves, since they are configured with the same key.
Gomatic
Update: 10.8.2017
The gomatic project has been updated to support GoCD v17.7. A somewhat more complex workflow configured via a gomatic script can be seen in the dedicated folder of the project.
To provision the server started with docker-compose up -d, after the server has started, make sure gomatic 0.5.0+ is installed (sudo pip install gomatic), and run python configure.py.
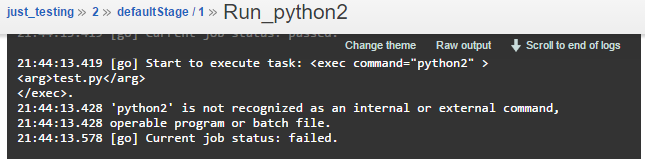
When the jobs have run, the following can be seen:
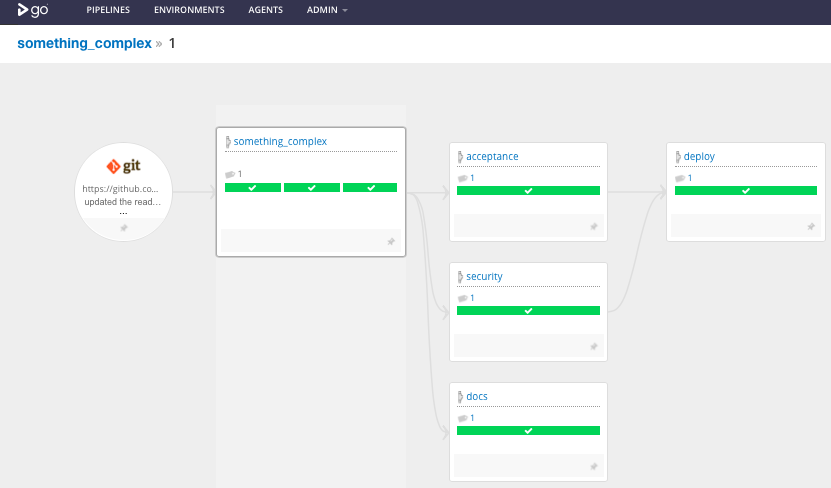
Other CI Tools
A comparable exercise can be performed with almost any tool. Some tools that are natively based on the concept of pipelines are Concourse CI and Drone that both use Docker as build agents (runners). Drone even comes with its own Docker-Compose config. Concourse can be bootstrapped via Vagrant.
A significant difference of GoCD to the more recent tools is its platform-independence. Sometimes, building inside a container is not a choice, e.g. on Windows. GoCD agents can run anywhere, where a JRE8 can run, thus, increasing its reach. A phoenix environment including Windows agents can be achieved with some effort using Chocolatey → Packer → Terraform/Vagrant.
Conclusion
This article has described an experiment to rather quickly arrive at a self-contained and self-provisioned Continuous Delivery infrastructure consisting of “Phoenix Servers” – a phoenix infrastructure.
While the result is rather humble, it demonstrates that continuous delivery techniques can be applied to a continuous delivery infrastructure itself. Using Docker Compose allowed to prototype a distributed development-supporting application and its configuration on a local developer machine with a potential to transfer the prototype into real use.
All this would be impossible without a huge network, or, I’d say, a universe, consisting of online services running and providing open source software that is created by a large number of open source communities, and a yet larger number of individuals collaborating in various ways to envision, create, maintain, and run it. Moreover, times are such that one can experience successful transition of proprietary software into open source (GoCD), and companies, building business around open source software. The OSS ecosystem is a distributed, self-directing system that catalyzes idea creation, mutation and destruction much faster that most smaller systems can do. For the moment, I hope, there is no going back.
Repository
The Github repository to run the self-contained infrastructure can be found here: gocd_docker_compose_example.
The repository can be used to bootstrap demos, further experiments and proofs of concept.
Disclaimer
This post, as any other post on my blog, is not advertisement, and no affiliation or endorsement exists. It is a write-up of my personal experiments, experiences and opinions. The results obtained here can most certainly be achieved using other tools and technologies.