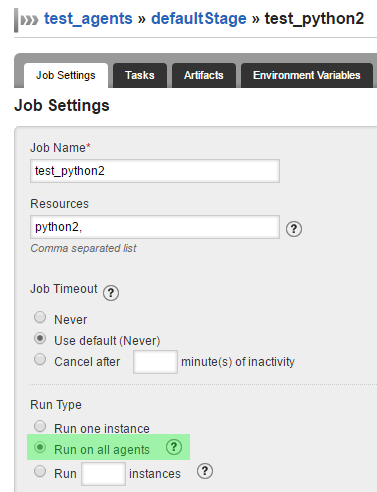
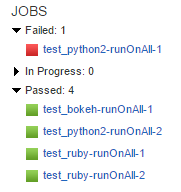
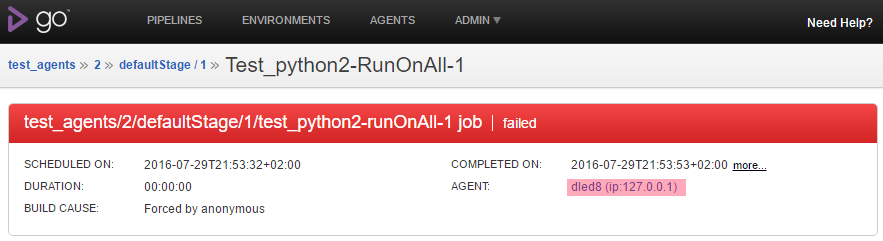
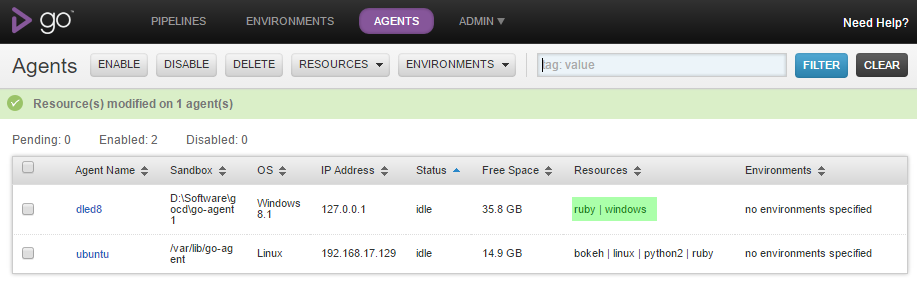
Motivation
It occurred to me that I was missing Ruby’s 42.times do ... in C++. While a loop is still imperative, the inspiration to write the folowing code and the post came after watching the talk “Declarative Thinking, Declarative Practice” by Kevlin Henney. Thus, let it be a “declarative imperative”. While there’s no explicit intended use for the following code, it could make some tests read a bit less verbose. An implementation should be dependency-free, minimalist and copy-paste-able.
42_times([]{
do_something();
});
First version
Luckily, C++11/C++14 feels like a new language[1. the original quote by Bjarne Stroustrup is about C++11] and has a nice feature that allows to fulfill wishes: user-defined literals. Thus, having settled on the implementation strategy, here’s how “.times” can look like in C++ as of today:
#include <iostream>
struct execute {
const unsigned long long n;
template<typename Callable>
void operator() (Callable what) {
for (auto i = 0; i < n; i++)
what();
}
};
execute operator"" _times(unsigned long long n) {
return execute{n};
}
int main() {
3_times([]{
std::cout << "bla" << std::endl;
});
auto twice = 2_times;
twice([]{
std::cout << "blup" << std::endl;
});
}
g++ -std=c++14 example.cpp & ./a.out
↓
bla bla bla blup blup
I’d guess, this idea occurred to a number of people already
Update 1: loop index
With two simple options: with a counter and without the counter available in the closure:
#include <iostream>
#include <functional>
struct execute {
const unsigned long long n;
void operator() (std::function<void()> what) {
for (auto i = 0; i < n; i++)
what();
}
void operator() (std::function<void(unsigned long long)> what) {
for (auto i = 0; i < n; i++)
what(i);
}
};
execute operator"" _times(unsigned long long n) {
return execute{n};
}
int main() {
3_times([]{
std::cout << "bla" << std::endl;
});
auto twice = 2_times;
twice([]{
std::cout << "blup" << std::endl;
});
3_times([](unsigned long long i) {
std::cout << "counting: " << i << std::endl;
});
}
↓
bla bla bla blup blup counting: 0 counting: 1 counting: 2
Update 2: benchmark
A simple benchmark attempt shows that the modern C++ compilers can optimize a for loop that doesn’t produce side effects better than the code above. However, not all code needs to sacrifice readability for performance. If the loop is not on the critical path, it probably doesn’t need to be optimized, especially, if it’s just a test.
After some tinkering to disable optimizations for the function call, here’s a hayai-based benchmark:
struct TimesVsLoop : public ::hayai::Fixture{
static int v;
static void do_something() {
v = v % 41 + 1;
}
static void do_something(unsigned long long i) {
v = (i + v) % 41 + 1;
}
};
int TimesVsLoop::v = 0;
BENCHMARK_F(TimesVsLoop, Times_Without_Index, 10, 100)
{
1000000_times([]{
do_something();
});
}
BENCHMARK_F(TimesVsLoop, Loop_Without_Index, 10, 100)
{
for (int i = 0; i < 1000000; i++) {
do_something();
}
}
BENCHMARK_F(TimesVsLoop, Times_With_Index, 10, 100)
{
1000000_times([](unsigned long long i){
do_something(i);
});
}
BENCHMARK_F(TimesVsLoop, Loop_With_Index, 10, 100)
{
for (int i = 0; i < 1000000; i++) {
do_something(i);
}
}
int main()
{
hayai::ConsoleOutputter consoleOutputter;
hayai::Benchmarker::AddOutputter(consoleOutputter);
hayai::Benchmarker::RunAllTests();
return 0;
}
g++ 1_benchmark.cpp -std=c++14 -O3 -I/usr/local/include/hayai && ./a.out
↓
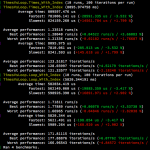
A performance hit is observable, but is probably insignificant in relevant use-cases:
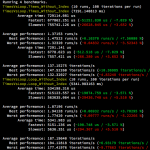
Update 3: a short metaprogram
In order to address the issue of the std::function overhead, Kirk Shoop (@kirkshoop) has posted an alternative version with a small metaprogram:
struct execute {
const unsigned long long n;
template<typename F, class Check = decltype((*(F*)nullptr)())>
void operator() (F what, ...) {
for (auto i = 0; i < n; i++)
what();
}
template<typename F, class Check = decltype((*(F*)nullptr)(0))>
void operator() (F what) {
for (auto i = 0; i < n; i++)
what(i);
}
};
This version appears to perform as good, if not sometimes better (an OS fluke, perhaps?) than the raw loop:

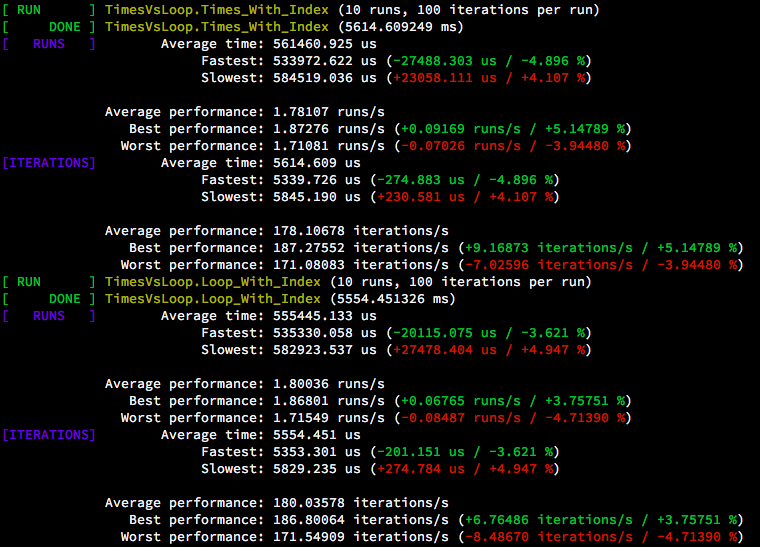
Update 4: CppCast & benchmark @ Github
This blog entry was briefly discussed in CppCast’s episode Catch 2 and C++ the Community with Phil Nash. Further ideas, reflections and analyses are welcome!
Benchmark code: cpp_declarative_times/github.com
Update 5: yet more declarative & responses
Jon Kalb has posted a very clear article with an in-depth take on a traditional C++ approach to implementing N_times(...). The Reddit responses point to the Boost.Hana implementation. These responses are in a way in tension with the original intent of writing a minimum sufficient amount of code to achieve the ruby-like syntax. However, indeed, a typical C++ solution involves metaprogramming partly to ensure that other uses apart from the one originally in mind are safe. The discussion of that phenomenon should be part of a separate article.
The other mentioned (metaprogramming) approaches inspire me to create an even more special [2. as in, opposite to generic], but still a “character-lightweight” solution. Coming back to declarative thinking and explicit and clear intent, a much simpler resolution of the two overloads can be achieved by simply creating another operator for the index overload:
struct execute_with_index {
const unsigned long long count;
template<typename CallableWithIndex>
void operator() (CallableWithIndex what)
{
for (auto i = 0; i < count; i++)
what(i);
}
};
execute_with_index operator"" _times_with_index(unsigned long long count)
{
return { count };
}
↓
1000000_times_with_index([](unsigned long long i) {
do_something(i);
});
this addition to the initial version solves the problem with the overloads and avoids both metaprogramming and std::function.
Next update: a more generic loop and CRTP.